, dev
Optimizing Pixar’s USD Compile Time
It’s been a long while since I’ve been wondering how I could possibly contribute to bringing a positive environmental impact to life by using my dev skills.
The opportunity finally showed up while doing some work on Pixar USD’s—I noticed that its codebase took around 90 minutes to compile on my laptop (Intel i7-7700HQ, Ubuntu 20.04) using a single thread. It seemed huge.
Even though this might not have the greatest impact in reducing energy waste, it was still an actionable item and could prove somewhat useful.
After all, USD is becoming mainstream across several industries now and with the amount of developers around the world working on improving its core, and the number of CI servers compiling the codebase over and over again before running tests, I thought... why not giving this a go? If all it does is to help with iteration times for all these developers, it’d still be a win!
Definitely Not Zero Cost Abstractions
I know it, you know it, we all know it—C++’s “zero cost abstractions” do in fact have a non-negligible cost, both in increased maintenance complexity but also in compile times. Right?
But still... how could a codebase possibly take 90 minutes to compile!? I was intrigued.
I fired up Aras Pranckevičius’s awesome compiler profiler and immediately got a clear picture of the problem.
*** Expensive headers:
972063 ms: /opt/boost/1.70.0/include/boost/preprocessor/iteration/detail/iter/forward1.hpp (included 13959 times, avg 69 ms), included via:
wrapTimestamp.cpp.o pyUtils.h pyInterpreter.h object.hpp object_core.hpp call.hpp arg_to_python.hpp function_handle.hpp caller.hpp (320 ms)
...
904090 ms: build/usd/include/pxr/usd/usd/prim.h (included 369 times, avg 2450 ms), included via:
modelAPI.cpp.o modelAPI.h apiSchemaBase.h schemaBase.h (3114 ms)
...
887681 ms: build/usd/include/pxr/base/tf/pyObjWrapper.h (included 993 times, avg 893 ms), included via:
aov.cpp.o aov.h types.h value.h (1567 ms)
...
838714 ms: build/usd/include/pxr/usd/usd/object.h (included 374 times, avg 2242 ms), included via:
wrapUtils.cpp.o wrapUtils.h (3054 ms)
...
835586 ms: build/usd/include/pxr/base/vt/value.h (included 894 times, avg 934 ms), included via:
aov.cpp.o aov.h types.h (1702 ms)
...
Yes, that’s right. Over 900,000 ms were spent on compiling some of these headers! That’s more than 15 minutes per header because they are being recompiled over and over again in hundreds, if not thousands, of compilation units. It’s just nuts that C++ encourages this.
Remember that C++ is based on C, and that C was designed to only have simple interfaces exposed in the header files (.h), while source files (.c) are reserved for their implementation. Header files were never meant to include actual implementation logic, and yet it’s exactly what C++ pushed for with templates. Take a few header files that include other header files that involve the STL, and there we have it—our definitely non-zero cost abstraction.
Tackling the Issue at Its Source
We now know that C++’s design is promoting long compile times, but what would it take then for developers to workaround this pitfall?
Well, if we’re fortunate enough to start a new C++ project from scratch, let’s just use headers how they were meant to be used in the first place, duh?
Seriously, it’s absolutely feasible to:
- write headers that define C-like interfaces as much as possible—ban STL data types, use raw pointers, and avoid templates unless strictly necessary.
- have headers that do not include other headers (with a few, rare, exceptions).
- and... that’s it!
Yes, it does require a certain paradigm shift but it’s not all that unrealistic. In fact it’s exactly how Our Machinery has been doing it for their game engine, as described in their article Physical Design of The Machinery.
After reading that article, I also have experimented with that approach in my personal work, such as Zero: A Bunch of Single-File Libraries for C/C++ for example, and although my experiments were on projects of a much smaller scale than The Machinery or USD, I still found it fairly challenging to undo my C++ habits at first, but it quickly became a much more natural process afterwards.
And if I managed to do it, I’m sure you can too!
Tackling the Issue After the Fact
Optimizing compile times on existing C++ projects without making breaking changes to their API is a whole different challenge. A much bigger one than I anticipated when I started to dive head first into doing just that for USD.
Strong from the profiling results, I knew what I needed to do: add support for unity builds. This way, instead of having an enormous amount of tiny compilation units, we’d have only a handful of larger ones and we won’t end up having to recompile the same expensive headers as many times.
“Easy-peasy”, I thought.
I started by modifying the project’s CMake configuration in order to make it create a new .cpp file for each module (e.g.: pxr/base/arch) that’d include all the other source files from the same module, and to make it compile just that one file instead of the other ones.
Not So Fast
Of course unity builds only work if all identifiers in the concatenated source files are unique. Which wasn’t the case in USD’s codebase.
Another less obvious issue is that some symbol resolution became ambiguous, as demonstrated in the following example:
using namespace boost;
using namespace std;
tuple foo; // is it “boost::tuple” or “std::tuple”?
Hence the work required was two-fold:
- avoid identifiers clashing by wrapping them all in a unique namespace.
- flatten all the namespaces by removing
usingstatements and referencing each symbol with their full name.
Early Results
I started to do these changes through a lot of search and replace directly within my IDE, sometimes involving some advanced regular expressions, but it quickly became apparent that this wouldn’t cut it. It was both too tedious and error-prone.
I still decided to pursue this approach just enough to cover a couple of modules, as to get an idea of whether I was going in the right direction.
Many hours later spread over a few weeks, I finally finished converting the pxr/base/arch and pxr/base/tf modules. The result was quite encouraging with a 4x speed up!
That was 2 modules done. Cool, now onto finding a more humane approach to refactoring all of the 55 modules, ahem.
Using the AST
I had to find a way to somehow automatize the refactoring. Not only that but, unlike a regular expression approach, I wanted the process to be done in a semantically robust fashion as to give me more confidence that the changes done would be valid.
Working at the AST level seemed like the obvious choice and I also kinda liked the idea of learning a new API. So I jumped onto the opportunity to get started with Clang’s AST API, yay!
“Surely it should be easy to find all the symbols in a codebase and prefix them with a namespace using the AST”, or so I thought. He he he, how naive of me.
I know it, you know it, we all know it—C++ is an (unnecessarily) complex language. And it turns out that this complexity is fairly well reflected in Clang’s AST API.
I’ll skip the details but it turned out to be a LOT of pain and to be mentally draining.
It took me months to iterate on my refactoring tools, with many setbacks, in order to get them as close as possible to the desired result. But, despite my perseverance, I just could not figure out how to make the refactoring process 100% automatic. There were always some bits of code that needed to be manually patched here and there after running the tools.
In fact, Clang’s AST API operates after the C++ preprocessor pass has finished evaluating, meaning that any code wrapped into #if/#ifdef statements might be discarded and left untouched by the refactoring tools. As a result, since I’ve run these tools using an Ubuntu environment, some code paths specific to Windows, macOS, Metal, and others, are required to be manually patched.
Final Results
Despite all the adversity, I still managed to refactor the whole USD codebase and to make it compile using an unity build approach. Did the early results carry over?
Yeah, mostly! I mean, look at this sexy graph!
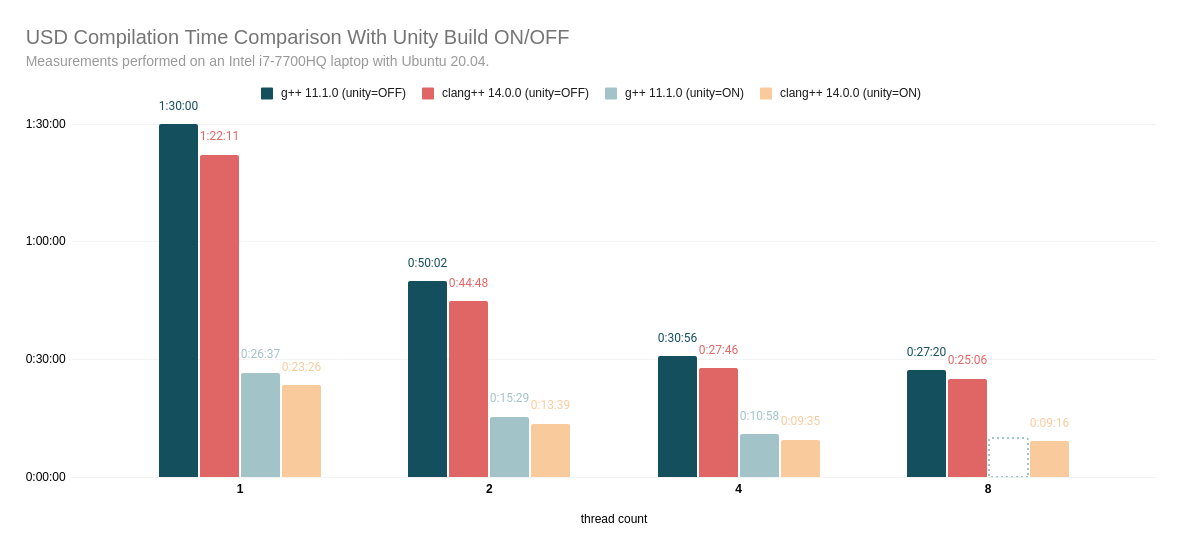
You’ll note that the timings for g++ 11.1.0 (unity=ON) with 8 threads are only an estimate, and that’s because my laptop runs out of memory for that one.
Overall, that’s still a speed-up of 2.7-3.5 times on my laptop. The compilation that took 90 minutes on a single thread now finishes in 26 minutes.
Which is admittedly still a lot but it’s a start.
Still Want to Know More?
You might find what you’re looking for in this pull request on GitHub.
As for the refactoring tools, they’re available on a GitHub repository.
What’s Next?
You know what would be fun? Optimizing the compile times of the LLVM project... tee-hee!